

咨询热线
400-123-4567
400-123-4567

是一款十分优秀的语法解析工具,由于其优秀的能力被用于HIive,Spark, 等大型的开源项目中。通过学习的使用,我们可以构建自己的语法解析方法。
接下来我们看看的基础入门
首先准备一个g4后缀的语法规则文件,内容如下:
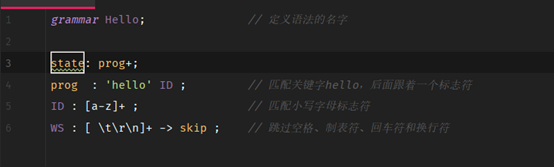
grammar Hello; // 定义语法的名字
prog : 'hello' ID ; // 匹配关键字hello,后面跟着一个标志符
ID : [a-z]+ ; // 匹配小写字母标志符
WS : [ \t\r\n]+ -> skip ; // 跳过空格、制表符、回车符和换行符
简单介绍一下:

: 语法的名称,与文件名名称一直,如上文件名称为Hello.g4
规则:即语法分析规则,以小写字母开头的就是 规则,上方的prog就是语法解析规则,名称可以自定义,当作变量名称可以更加方便的理解,可以看到prog的内容是 ‘hello’ 加上一个 ID的符号,ID是词法规则,prog这个语法规则会匹配到hello,然后将后续的部分交给词法,的解析顺序是从上往下解析的,最上方的规则为根语法规则。
Lexer 规则:即词法规则, 以大写字母开头的就是Lexer规则,词法规则可以放入规则中,去匹配语法分析规则中的单词,例如上面的ID使用了正则规则[a-z]+,就可以匹配到所有的小写字符,WS匹配到了空格、制表符、回车符和换行符,并会将其跳过。Lexer 规则无论写在文件的哪个位置,都会被排在 规则下面。
用以上的语法去解析’hello world’,则可以得到语法树
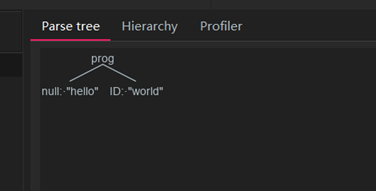
可以看出,语法解析器成功的匹配到了hello,而词法解析器ID也成功的匹配到了world这个单词。
同时语法解析器也可以通过别的语法解析器进行拼接,新增一个语法解析器,state为’prog+’,即一个或多个prog语法的解析。
输入’hello world hello antlr’,即可得到如下语法树
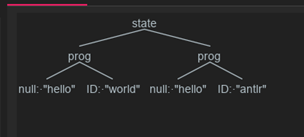
以上,就是最基础的语法介绍,即Antlr的语法解析器和词法解析器的使用方法,后续会继续进一步讲解语法解析器和词法解析器的使用方法以及其他的一些语法规则。